This post is the second in a series of posts about my CS244 project, ONCache. The first post discusses Kubernetes networking and the technical details behind it – specifically, how it handles networking and the implementation of overlay networks. If you haven’t read it yet, I highly recommend doing so for the necessary background.
Speeding up overlay networks
At last, we can finally introduce ONCache: A Cache-Based Low-Overhead Container Overlay Network.1 We can learn a lot from the title alone: ONCache is using a cache to reduce the overhead in their K8s overlay network. This makes sense as a target; overlay networks have a relatively expensive encapsulation / decapsulation process since the network plugin must look at the packet’s destination, find the appropriate endpoint and associated routing information, track the connection, possibly filter the packet, and send it on its way (doing the inverse on the ingress side).
Personal note: I really like this paper is that it is a very clear example of the how the key principles of system architecture (as taught by Caroline Trippel) can provide substantive wins. In this case, our tool is caching and we gain a good percentage in performance basically for free.
For the first third of the paper, the authors do the hard work of determining exactly why overlay networks are slow and where those time losses are. As with most projects in CS systems, we’re competing against doing “nothing” – in this case, user-space application to application communication which the authors call “bare metal”.2 Additionally, the authors are working with two specific overlay networks: Antrea and Cilium.
I highly recommend you read the original paper which explains these results in detail (see figure 2) but the major takeaways is that overlay networks lose time on the veth pair traversal (to get from the container network namespace to the host namespace), Open vSwitch (or an eBPF equivalent in Cilium’s case) for packet filtering and intra-host routing, and the encapsulation / decapsulation protocol overhead. The goal of ONCache is to reduce the overhead at each of these steps, and they accomplish this by caching the results of multiple invariants during the lifetime of a connection:
- Connection tracking: considered “established” once both sides of a connection have been observed and remains until the connection ends
- Packet filtering: allowed or denied based on the “5-tuple” (source IP, source port, destination IP, destination port, and protocol) and connection state, both of which are unchanged once a connection flow is established.
- Intra-host routing: routing decisions are the same for a given destination pod IP.3
- Encapsulation headers: most of the headers for the encapsulated packet (which we’ll take a closer look at in a bit) are the same, with only the length, ID, and checksum, and source port changing.
Our goal is to cache all these invariants and once the flow is established, jump from the beginning to the end of the networking stack and inject all of the necessary information into the packet and update as little as possible.
Gotta go fast
Now that we have a lot of background under our belt from part one, we can finally get to implementation. As a reminder, our goal is to bypass the encapsulation portion of the networking stack between the container and the host interface. Let’s take a look at the networking stack for our host and container:
Our egress and ingress fast path will bypass the OVS and encapsulation stack by jumping from the host side of the veth to the host interface and vice versa. For egress, while it would be more efficient to jump from the container side of the veth to the host interface, the veth on the container-side cannot redirect packets to the host interface since it’s in an isolated namespace; note that this only affects the hook points for egress, or what stage in the networking stack that we observe and manipulate the packets. This isn’t an issue for ingress as we redirect directly to the “peer” (opposite) side of the veth.
In order to do this packet modification and redirection, we’re going to need to hook two programs into the network stack:
tc/egress: at the traffic control (TC) ingress4 point of the host-side vethtc/ingress: at the TC ingress point of the host interface
These two programs are going to be responsible for using the cached results based on those invariants from earlier (don’t worry, we’ll go back over them soon). But, since these programs are bypassing the networking stack by preceding it in either direction, we need a separate pair of programs at the very end of the networking stack to actually do the caching.
tc/egress_init: at the TC egress point of the host interfacetc/ingress_init: at the TC ingress point of the container-side veth
Note that our tc/ingress_init program can actually go inside the container since eBPF programs can share state across namespaces and these programs don’t modify any packets.
The caches
As a reminder from earlier, we have four invariants during the lifetime of a connection that we can rely on: connections are “established” once both sides are observed, packets filtering decisions are unchanged once a flow is established, and routing decisions / most of the encapsulation headers are the same for a given destination. Therefore, given an established connection, we should cache the filtering decision, and routing decision / encapsulation header values. In practice, this gives us three caches:
- Egress cache: map from container destination IP → (outer headers, inner MAC header, host interface index)
- Ingress cache: map from container destination IP → (container veth index, inner MAC header)
- Filter cache: map from (source IP, source port, dest IP, dest port, protocol) → (ingress allow/deny, egress allow/deny)
When using the egress cache, we’ll prepend the entire outer headers, change the inner MAC header, and change some values as needed (lengths, checksums, ports, etc.) and direct it to the correct outgoing host interface as there can be multiple. This captures the routing decision within the outer headers itself. When using the ingress cache, we chop off the outer headers, replace the inner MAC header, and send it to the destination container’s veth.
One small optimization for cache size that can be made is that all of the egress cache values are the same for a given host destination IP. ONCache therefore uses a two-layer egress cache:
- map from container destination IP → host destination IP
- map from host destination IP → (outer headers, inner MAC header, host interface index)
eBPF Implementation
Let’s get to work! We’re going to be using eBPF to create programs that can be directly run safely and performantly in the kernel. Basically, we write C code (plus some very useful helpful functions) that is compiled to a special intermediate representation defined by eBPF that can be loaded, statically verified for safety, and interpreted or just-in-time compiled by the kernel. While the rules for safety depend on a lot of factors, we must avoid unbounded loops or recursion, unchecked pointer accesses, deadlock, or read uninitialized memory.
eBPF also has a wide number of program types that all have different input parameters, capabilities, and restrictions. While we have multiple options for network programs, we want a program that allows us to modify packets, redirect them, and classify (allow or block) them. When these programs were introduced, none of them had access to all of the features we need. The closest were the traffic control (TC) classifier (BPF_PROG_TYPE_SCHED_CLS) and TC action (BPF_PROG_TYPE_SCHED_ACT) that, when combined, allow us to manipulate all traffic. However, with Linux Kernel 4.4,5 we gained the direct-action flag that allows the TC classifier to also modify packets. So, we’re going to go with BPF_PROG_TYPE_SCHED_CLS plus the direct-action flag.
Data structures
Lastly, we need some way to persist the cached results and allow our programs to talk to each other. We’ll do this using key-value maps, specifically, the LRU hash map (BPF_MAP_TYPE_LRU_HASH) for fast key-value lookups and a limited maximum size. We’re also going to pin our maps so that we can be 100% sure that only one instance of each BPF object exists and is shared. This also has the very nice side effect of allowing us to read the map at any time using the BPF filesystem (/sys/fs/bpf).
Here’s what our maps look like
// Structs and typedefs60 collapsed lines
typedef __be32 addr_t;
// See https://datatracker.ietf.org/doc/html/rfc7348#section-5// Note: it's probably ok for GENEVE assuming no variable-length options// See https://datatracker.ietf.org/doc/html/rfc8926#section-3.1#define VXLAN_HEADER_LEN 8
// Outer header structure: Ethernet + IP + UDP + VXLAN// See https://datatracker.ietf.org/doc/html/rfc7348#section-5typedef struct outer_headers_t { struct ethhdr eth; struct iphdr ip; struct udphdr udp; __u8 vxlan[VXLAN_HEADER_LEN];} __attribute__((packed)) outer_headers_t;
// Inner header structure: Ethernet + IP// See https://datatracker.ietf.org/doc/html/rfc7348#section-5typedef struct inner_headers_t { struct ethhdr eth; struct iphdr ip;} __attribute__((packed)) inner_headers_t;
// Encapsulated header structure: outer + inner// See https://datatracker.ietf.org/doc/html/rfc7348#section-5typedef struct encap_headers_t { outer_headers_t outer; inner_headers_t inner;} __attribute__((packed)) encap_headers_t;
// Egress cache L2: host destination IP -> (outer headers, inner MAC header,// host interface index)struct egress_data { outer_headers_t outer; struct ethhdr inner; __u32 ifindex;};
// Ingress cache: container destination IP -> (veth interface index, inner MAC// header)// vindex maintained by daemon, inner MAC header maintained by eBPFstruct ingress_data { __u32 vindex; struct ethhdr eth;} __attribute__((packed));
// Filter cache: (source IP, source port, dest IP, dest port, protocol) ->// (ingress action, egress action)struct flow_key { __u32 src_ip; __u16 src_port; __u32 dst_ip; __u16 dst_port; __u8 protocol;} __attribute__((packed));
// Filter action: ingress and egress allow (1) or deny (0)struct filter_action { __u8 ingress : 1, egress : 1;};// Maximum number of entries in the caches#define MAX_ENTRIES 4096
// Egress cache L1: container destination IP -> host destination IPstruct { __uint(type, BPF_MAP_TYPE_LRU_HASH); __type(key, addr_t); __type(value, addr_t); __uint(max_entries, MAX_ENTRIES); __uint(pinning, LIBBPF_PIN_BY_NAME);} egress_host_cache SEC(".maps");
// Egress cache L2: host destination IP -> (outer headers, inner MAC header,// host interface index)struct { __uint(type, BPF_MAP_TYPE_LRU_HASH); __type(key, addr_t); __type(value, struct egress_data); __uint(max_entries, MAX_ENTRIES); __uint(pinning, LIBBPF_PIN_BY_NAME);} egress_data_cache SEC(".maps");
// Ingress cache: container destination IP -> (veth interface index, inner MAC// header)struct { __uint(type, BPF_MAP_TYPE_HASH); __type(key, addr_t); __type(value, struct ingress_data); __uint(max_entries, MAX_ENTRIES); __uint(pinning, LIBBPF_PIN_BY_NAME);} ingress_cache SEC(".maps");
// Filter cache: (source IP, source port, dest IP, dest port, protocol) ->// (ingress action, egress action)struct { __uint(type, BPF_MAP_TYPE_LRU_HASH); __type(key, struct flow_key); __type(value, struct filter_action); __uint(max_entries, MAX_ENTRIES); __uint(pinning, LIBBPF_PIN_BY_NAME);} filter_cache SEC(".maps");Initialization programs
Now that we have our shared maps, we can work on initializing our cache! Since you can view our implementation (which has a ton of comments), I think it’s better if we take a look at the overall process rather than worrying about the code. Starting with the egress initialization program which sits at the egress point of the host interface, we will:
- Check if the packet is encapsulated (VXLAN or Geneve)
- This requires us to check if the packet is big enough and if it’s an IP packet containing a UDP packet with a VXLAN/Geneve port. In the real world, you might also want to check the version of the encapsulation header.
- We then generate the
flow_keyfor the packet and ignore it if it’s not a TCP or UDP packet internally. - Check that the packet is marked as established and missed.
- We want to make sure that the packet is part of an established flow and wasn’t modified by the other egress program at the beginning. To do this, we abuse the IP type of service field and reserve one for our overlay network to mark the flow as “established” and the other for our egress program to mark a packet as “missed”.
- Fill in both egress caches and the filter cache. If our flow exists in the filter cache and we’re “observing” it this late, it means it must have been allowed and therefore we should update the filter cache.
- Clear the missed and established TOS bits.
Ingress initialization, which sits at the ingress point of the veth container-side, is similar but easier:
- Get the
flow_keyfor the packet and ignore it if it’s not TCP or UDP. - Check that the packet is marked as established and missed.
- Make sure that there’s a cache entry for our container’s IP.
- Wait, what? This seems like a circular dependency! What makes the ingress side complicated is that our ingress program doesn’t know which veth it’s attached to, but it needs to to have a populated cache entry. Later, our user-space daemon will populate the veth index of the cache entry at container startup.
- Fill in the ingress and filter cache.
- Clear the missed and established TOS bits.
Great, we’re done!
Bypass programs
Now for the fun stuff – doing the bypass. Let’s start with egress, which is attached at the ingress (outgoing) point of the veth host-side:
- Get the
flow_keyand ignore it if not TCP or UDP. - Get the egress and filter cache data. Mark as missed and ignore the packet if any data is missing or not allowed by the filter cache.
- Check the ingress cache for the sender IP.6 Mark as missed and ignore if missing.
- Get the hash of the packet prior to encapsulation. According to the docs, the hash is actually “calculated from the flow information of the packet,” meaning the 5-tuple which we need!
- Make the packet bigger for the encapsulation headers!
- This is the single most complicated step. The helper function
bpf_skb_adjust_roomdoes most of the heavy lifting, but there are a bunch of flags to select. We use theBPF_ADJ_ROOM_MACmode since we’re adding space at the earliest level (between the L2 ethernet and L3 IP layers) and grow by amountsizeof(outer_headers_t). We then use the following flags:BPF_F_ADJ_ROOM_FIXED_GSO: Don’t adjust the generic segment offload size.BPF_F_ADJ_ROOM_ENCAP_L3_IPV4: This is for an IPv4 tunnel.BPF_F_ADJ_ROOM_ENCAP_L4_UDP: This tunnel works over UDP.BPF_F_ADJ_ROOM_ENCAP_L2_ETH: This tunnel needs an ethernet header.BPF_F_ADJ_ROOM_ENCAP_L2(sizeof(struct ethhdr)): This L2 header is the same size as an ethernet header.
- This is the single most complicated step. The helper function
- Set the outer headers from the cache.
- Update the UDP length, source port, IP length, and IP checksum.
- Updating the IP checksum is a pain since it’s incremental, meaning the function
bpf_l3_csum_replaceneeds the byte offset, original value, new value, and size.
- Updating the IP checksum is a pain since it’s incremental, meaning the function
- Redirect the packet (
bpf_redirect) to the host interface.
Ingress, which sits at the ingress point of the host interface, is again simpler and easier:
- Check if the packet is encapsulated.
- Check if the packet matches the IP and ethernet address of the host.
- We pass this data in as a static global variable and set it with the daemon.
- Get the ingress and filter cache data. Mark as missed and ignore the packet if any data is missing or not allowed by the filter cache.
- Check the egress host cache for the sender IP. Mark as missed and ignore if missing.
- Make the packet smaller!
- Again, we’re using
bpf_skb_adjust_room, but this time it’s nice and easy since we’re shrinking the packet. We use theBPF_ADJ_ROOM_MACmode and “grow” by amount-sizeof(outer_headers_t)with no flags.
- Again, we’re using
- Set the inner headers.
- Redirect the packet to the peer (
bpf_redirect_peer) of the veth interface.
Nice and easy! For our code to actually work, we’re going to need to do some plumbing using a user-space daemon but can actually do some testing to make sure we pass the eBPF verifier!
Verifying our eBPF
To test if our eBPF code (or any eBPF code) passes verification, we want to load it into the kernel into some dummy component that, very importantly, isn’t doing anything. For traffic control programs, we can do this with a dummy virtual IP link, add a clsact queuing discipline (qdisc), and then add our programs as direct-action (da) filters. It doesn’t actually matter if we add the filters as ingress or egress since the context buffer is the same and we’re just checking if they pass static verification.
For reference, this is the testing script I was running:
sudo ip link add dummy0 type dummysudo ip link set dummy0 upsudo tc qdisc add dev dummy0 clsactsudo tc filter add dev dummy0 egress bpf da obj ./ebpf_plugin.o sec tc/egress_initsudo tc filter add dev dummy0 ingress bpf da obj ./ebpf_plugin.o sec tc/egresssudo tc filter add dev dummy0 ingress bpf da obj ./ebpf_plugin.o sec tc/ingress_initsudo tc filter add dev dummy0 ingress bpf da obj ./ebpf_plugin.o sec tc/ingresssudo tc qdisc del dev dummy0 clsactsudo ip link del dummy0Very important! Passing this does not say that your code is “correct” – just that it passes the required safety checks with respect to kernel stability. It does not do any reasoning about correctness. Your code could still do something dumb like drop every packet.
User-space management
So far, we’ve gotten through all of the fun and technically interesting parts. This, by contrast, is relatively boring. If you thought the previous section was somewhat hand-wavy, hold on to your windbreakers. You can, and should, take a look at the source code.
We’re working with Go since it’s very common in the eBPF and K8s space, meaning we have access to all the packages we need. To be honest, while I wanted to do this in Rust, having access to Goroutines simplifies a lot of this. On the other hand, half of the 835 lines of source code are probably error handling.
First, after doing some boilerplate stuff like opening an rtnetlink socket, we’re going to run all of the setup operations for the host. These only have to happen once at start, with just some teardown at the end.
- Create a
clsactqdisc for the host. - Load the eBPF program collection spec (
ebpf.LoadCollectionSpec)- This is just describes the collection of programs rather than actually converting them to runnable programs.
- Make a directory
/sys/fs/bpf/tc/globalsfor the pinned maps- This is mainly so we can defer a function that deletes the pinned map directory
- Load the eBPF collection into the kernel with the
PinPathoption as the directory we just made.- These programs and resources are now live in the kernel but aren’t attached to anything yet.
- Mount the host-attached
egress_initandingressprograms asdirect-action.- We do the mounting via file descriptor as a TC object with the
"bpf"attribute.
- We do the mounting via file descriptor as a TC object with the
- Set the global with the host IP and MAC.
- The Cilium eBPF tooling makes this really easy, as we can access the globals as a dictionary (i.e.
coll.Variables["host_interface"]). The annoying part is getting the struct in Go to match the binary layout of the eBPF struct. Make sure your endian order matches!7 This will be a theme for all eBPF object accesses :(
- The Cilium eBPF tooling makes this really easy, as we can access the globals as a dictionary (i.e.
- Set up the network plugin rules to mark connections as “established”. We’ll come back to this.
- Start watching for changes in containers or nodes.
Establishing connections
As we noted earlier, we have to make sure that we’re only ever acting on flows that our underlying network plugin is fully aware of. If we act too early, we risk caching something that is not invariant for the lifetime of the flow. To do this, we’re going to have our overlay network plugin mark the flow as “established” by setting a bit in the IP TOS. While you should be able to do this with any overlay network plugin, we’re going to look at how Antrea handles it.
Here are the default OVS flow rules from Antrea:
// Forward tracked flows from non-serivce connectionstable=ConntrackState, priority=190,ct_state=-new+trk,ct_mark=0/0x10,ip actions=goto_table:AntreaPolicyEgressRule
// Forward tracked flows from service connectionstable=ConntrackState, priority=190,ct_state=-new+trk,ct_mark=0x10/0x10,ip actions=set_field:0x200/0x200->reg0,goto_table:AntreaPolicyEgressRuleAnd here are our changes to set the 3rd bit of the IP TOS to 0x1 for all tracked flows:
// Forward tracked flows from non-serivce connectionstable=ConntrackState, priority=190,ct_state=-new+trk,ct_mark=0/0x10,ip actions=load:0x1->NXM_OF_IP_TOS[3],goto_table:AntreaPolicyEgressRule
// Forward tracked flows from service connectionstable=ConntrackState, priority=190,ct_state=-new+trk,ct_mark=0x10/0x10,ip actions=set_field:0x200/0x200->reg0,load:0x1->NXM_OF_IP_TOS[3],goto_table:AntreaPolicyEgressRuleWe do this by accessing the antrea-agent containers and use the ovs-ofctl command in the container.
Handling new containers
Now, we want to watch for new containers on our host so that we can attach all the necessary eBPF programs!
One of the issues with this is that, as we looked at in the previous post introducing K8s, there is a difference between Kubernetes pods and containers: as pods are the smallest deployable unit for K8s and are made up of multiple containers, we have to watch for new pods and introspect it to actually find the relevant container namespaces. In Go, we can set up a K8s watcher to subscribe to pod events and then, if the pod is healthy and belongs to our local node, we can initialize the container.
- Get the container information from the container runtime. We specifically care about the PID of the container process.
- K8s is entirely oblivious to these details as this is the responsibility of the CRI plugin. Interfacing with the runtime can be a bit annoying; for example, containerd requires opening a local gRPC connection to a unix socket.
- Once we have access to the container runtime, we have to query it for the container PID, which, for containerd, requires requesting the container status with verbose information and then using a json parser to extract the
pidentry.8
- Load the
ingress_initprogram into the container.- This is similar to earlier except we need to step into the container’s network namespace to access the container side of the veth.
- Important: because we’re going to be switching our namespaces which occurs at the process level, we run the risk of unexpected behavior if the Go runtime switches threads. You must lock the OS thread in the runtime so we don’t accidentally switch threads while in the container namespace.
- Then we can grab our current host namespace, get the container namespace from the PID. We can then step into the namespace (don’t forget to defer stepping back out!) and attach the eBPF program as normal.
- While we’re in the container namespace, we also grab the host veth index that corresponds to the container veth for later.
- Use the host veth index to attach the
egressprogram to the host-side veth. - Add the veth index into the
ingress_cacheeBPF map.- Note: the ethernet header value doesn’t matter.
Lastly, we add the container ID to a set to make sure we don’t re-initialize a container until it is terminated (or crashes).
Cache coherence
We’ve handled the most important part of ONCache: setting up the fast path for new containers. We luckily don’t really have to deal with new nodes since, if our daemon launches on startup, it handles all of that setup for us. However, with all caches, we have to deal with coherence when things disappear or change. Since we don’t have to deal with migrations in K8s, there are no relevant “change” events – just terminations. We specifically care about pod and node terminations. Furthermore, unlike pod and node setup in which we only “care” about local pods and nodes (there’s only one – the host), we now must observe the terminations across the K8s cluster.
Pod coherence
When a pod emits a deletion event, it’s likely because it either has succeeded (i.e. gracefully hit an exit condition) or has failed (i.e. too many crashes or deployment deletion). When this happens, we want to grab all of the containers in the pod and erase their information from the caches. How we handle the container depends on if it’s local or remote, but both are nearly identical.
- Local: remove the container IP key from the
ingress_cachemap. - Remote: remove the container IP key from the
egress_host_cachemap.
Node coherence
When a node emits a deletion event, something has probably gone wrong as nodes tend to be relatively stable. K8s thus often takes a long time to determine if a node has been lost. Lucky for us, we only have to handle deletion events for remote nodes.9 Similarly to a remote pod termination, we remove the node IP key from the egress_data_cache map.
Note that we don’t have to make any changes to the egress_host_cache map even though some of the entries may point to the deleted egress_data_cache entry. This is because we validate that both entries exist and consider it a cache miss if either is missing, leading to both entries being regenerated by our egress_init program.
Benchmarking
As we aimed to reproduce and validate the original paper’s results, we attempted to reproduce their experimental setup as closely as possible. To evaluate ONCache, the authors use three c6525-100g nodes on CloudLab, each with a 24-core (48 hyper-thread) processor and 100 GB NIC.10 Our topology used one controller node and two worker nodes as Kubernetes prevents scheduling containers on the controller by default. However, you can remove this restriction and allow scheduling on the controller – we saw no performance differences when doing this with two nodes.
Our benchmark script handles most of the complexity and the repository gives instructions for how to run our benchmarks, so we’ll instead take a look at the high-level methodology.
For our K8s testing, we spin up the total number of containers we’ll need for the entire test (32 in our case). We also reuse containers between tests for each flow count (1 to 32) and packet type (TCP or UDP). Both of these choices were made in the name of simplicity and have a negligible impact on performance. Idle containers have negligible resource usage as they’re either sleeping or awaiting a connection; reused containers have a negligible performance improvement as ONCache initializes its fast path extremely quickly (~30μs) compared to the length of the tests (60 seconds). We used 60-second tests in the same manner as the original paper, which put all of the clients on one machine and all of the servers on the other. Just like the original paper, we used iperf3 for throughput testing and netperf for request-response roundtrip time (RR).11
We ran our tests sequentially by number of flows (powers of two from 1 to 32), packet type (TCP or UDP), and benchmark (throughput or RR).12
Performance
We were able to replicate the results from the original paper, showing that ONCache reduces a significant amount of overhead in overlay networks. As done in the original paper, all data is the average of a single flow. Additionally, for all “CPU” graphs, utilization is normalized by the associated benchmark (throughput or RR) and scaled by Antrea’s value.
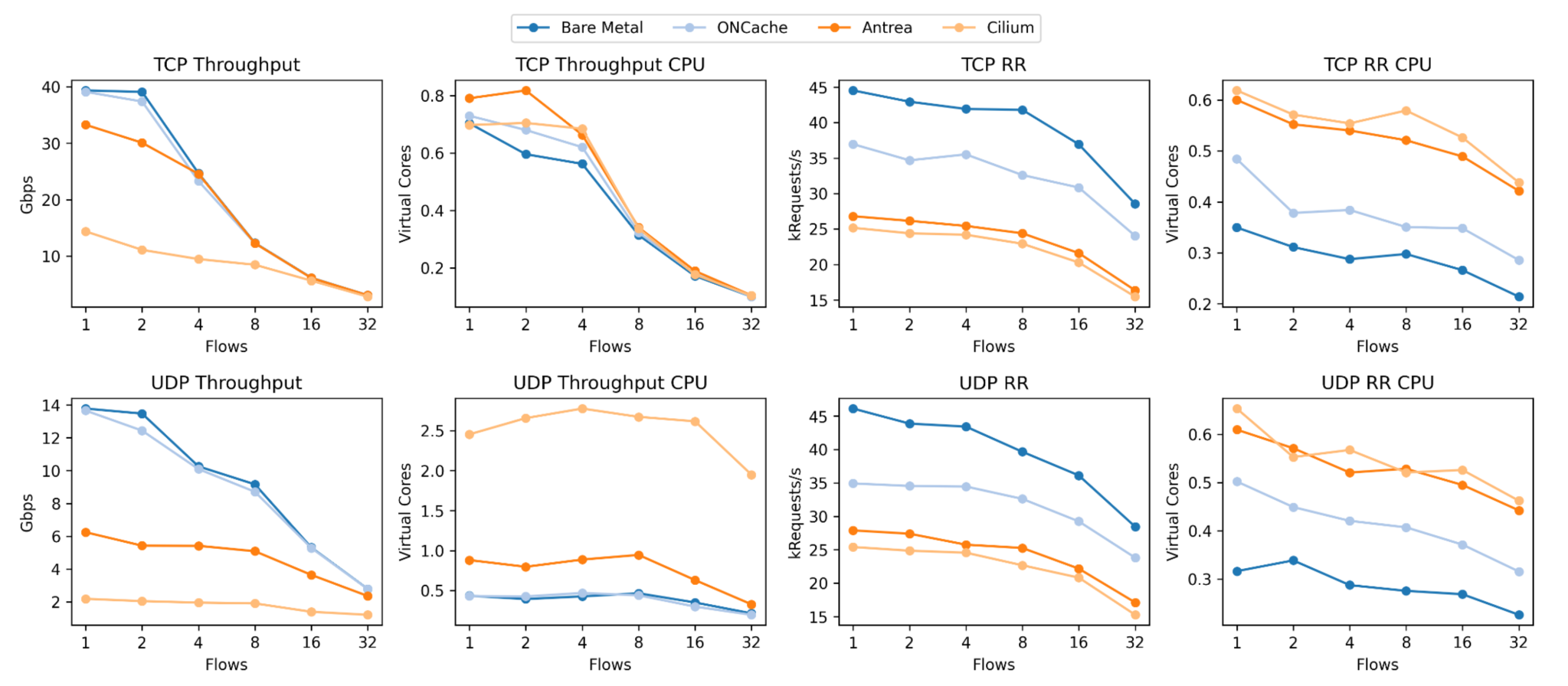
We found that ONCache, compared to Antrea for a single flow, provides 17% better throughput and a 38% better request-response transaction rate for TCP (119% and 25% respectively for UDP).Below are the same graphs paired with the original paper’s results, with our replication on the bottom of both sets of graphs.
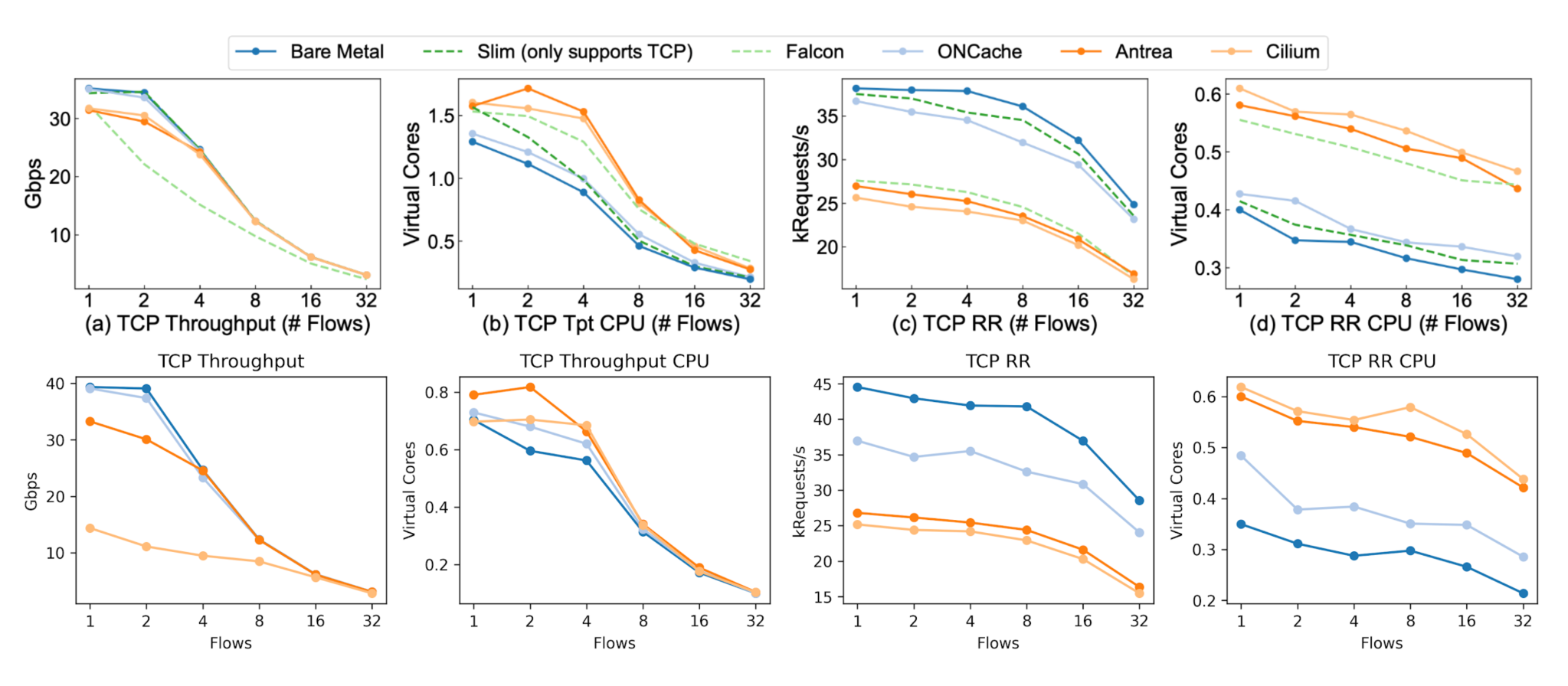
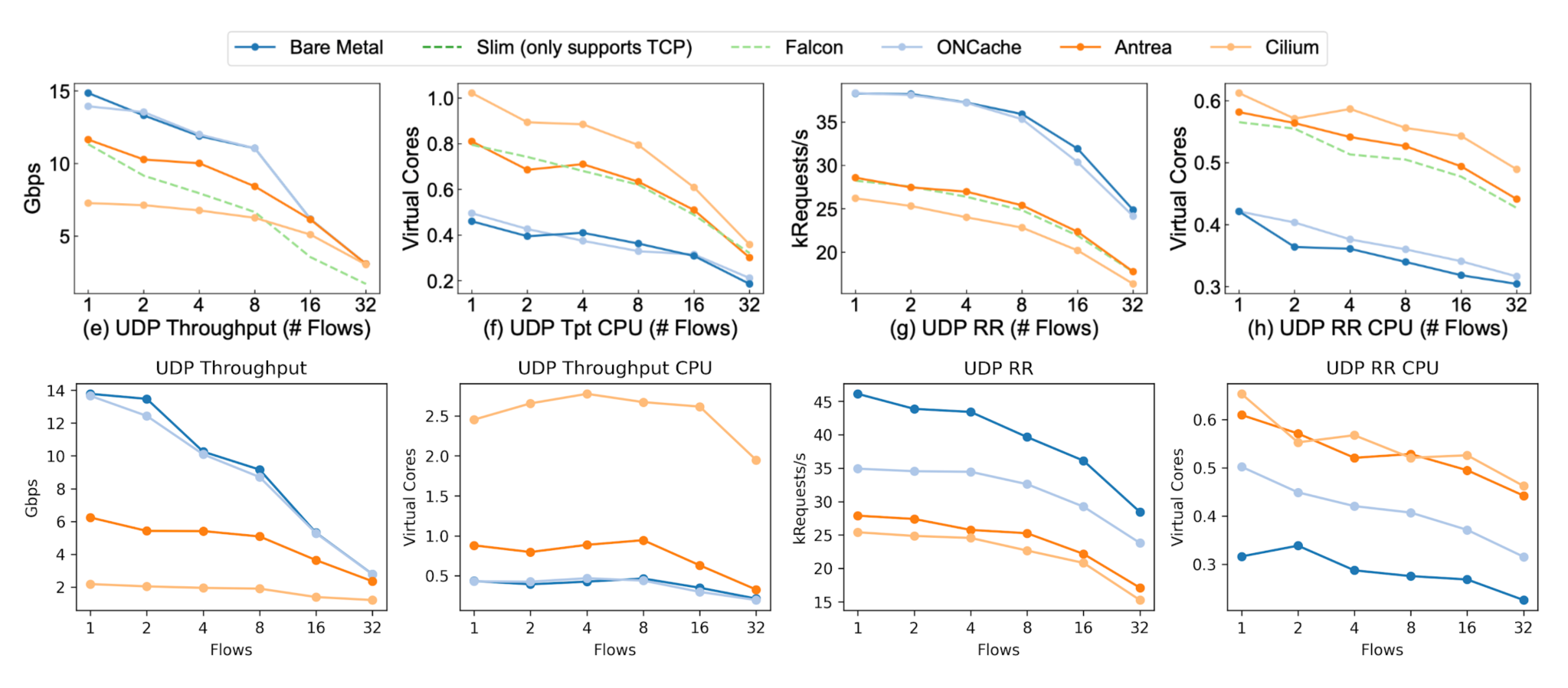
It’s important to note that our Cilium throughput was lower than expected for both packet types, and we can also see that UDP throughput for Antrea is much lower compared to the original results. We don’t have a good explanation for these at this time – if you have any idea what’s going wrong here, let me know.
The request-response results also show an obvious improvement for ONCache, with the results closely matching the original paper except for bare metal. Our RR CPU utilization for ONCache is slightly higher than expected (for both TCP and UDP) but is still lower than Antrea and Cilium. Additionally, bare-metal RR performance is much higher than expected for both packet types.13
Other findings
While this project was focused on Kubernetes and networking lessons as a while, we also discovered some differences between the Linux kernel versions that could majorly affect performance. Specifically, we found that both throughput and request-response rate vary drastically depending on the Linux kernel version used.
For instance (on the exact same hardware), while Linux 5.14 provides a bare-metal TCP throughput of 39.3 Gbps, Linux 5.15 gets 33.9 Gbps (-14%) and Linux 6.8 gets 30.1 Gbps (-23%). The same is true for TCP RR: -31% for Linux 5.15 and -34% for Linux 6.18 compared to Linux 5.14. Note that, as expected, we found no difference between Linux 5.14 on Ubuntu 20.04.6 LTS (which shipped with Linux 5.4) and Linux 5.14 on Ubuntu 22.04.5 LTS (which shipped with Linux 5.15).
We have no good explanation for this behavior at this time, but our best guess is that the Mellanox drivers might play better with certain Linux kernel versions, or some packet steering behavior that was advantageous to our benchmarks changed.
Conclusion
ONCache is a relatively simple tool that provides a substantial performance improvement for Kubernetes overlay networks, and we looked at exactly how it’s designed and implemented in this post. We also took a quick look at how it actually fairs in benchmarks and some other interesting tidbits we found along the way.
One question some readers might have is: why publish this? This post, unlike its predecessor, is more of an information dump and rather unspecific how-to guide instead of a more-educational piece. Additionally, depending on how you read into this post, you might assume that implementation was relatively straightforward given that its not original work. To some extent, you’re right. However, we ran into many roadblocks (i.e. the packet steering issues discussed in the previous post) and found a significant amount of documentation to be missing, unfinished, or wrong. Hopefully this post contains the answers to similar questions that we once had. If you don’t think so, ask me.
I’d like to thank the original authors of ONCache: Shengkai Lin, Shizhen Zhao, Peirui Cao, Xinchi Han, Quan Tian, Wenfeng Liu, Qi Wu, Donghai Han, and Xinbing Wang. This post would not exist without their hard work.
I’d especially like to thank Shengkai Lin, whose correspondence was extremely helpful to this project and solving many of our unexpected divergences during benchmarking.
Footnotes
-
Shengkai Lin, Shizhen Zhao, Peirui Cao, and Xinchi Han, Shanghai Jiao Tong University; Quan Tian, Wenfeng Liu, Qi Wu, and Donghai Han, Broadcom; Xinbing Wang, Shanghai Jiao Tong University ↩︎
-
Application to application communication is not really machine to machine or bare-metal. Kernel to kernel communication would be near optimal although I’m sure you could beat that with true bare-metal programming and optimizations. Nevertheless, app to app is what most users would typically see as best-case network performance. ↩︎
-
Huge caveat here. While we typically don’t have to deal with pod live migration (I’ll likely write a post about this someday), a pod could terminate on one machine and that IP address could theoretically be reused on a different machine. This is typically not an issue as most overlay networks give ownership of a subset (or multiple) of the routing CIDR for each node as it makes routing decisions faster. Even so, for large-scale deployments, the overlay network may choose to reclaim unused CIDR ranges from nodes if needed, or the node could die and be replaced by another with a different IP. We’ll discuss cache coherence later for these reasons. ↩︎
-
Why is it ingress? Think of a veth as a tube from one “space” to another with a checkpoint at each end. Egress is defined as “exiting” the space or data entering the tube, while ingress is “entering” the space or data exiting the tube. Thus, an outgoing packet from the container application goes through the egress checkpoint of the veth on the container side and through the ingress checkpoint of the veth on the host side (as it’s entering the “space” of the outer host). ↩︎
-
Technically, we also need
clsactqdisc, introduced in Linux Kernel 4.5, in order to havedirect-actionTC programs on the egress path. ↩︎ -
For this bypass to work correctly, it needs to be symmetric since the other end must be able to properly unwrap the internal ethernet header. ↩︎
-
You can make this process way easier by letting Cilium’s
ebpf-godo the compilation for you which will generate all of the structs with the correct layout. We had difficulty doing this and instead compiled our eBPF code separately and loaded it externally. ↩︎ -
I am a firm believer that programmers should be as idiomatic as possible, which thus means that I generally frown upon non-structured outputs and shell scripting in something like Go. Good interfaces should be providing stable and structured outputs instead of JSON. It’s OK if they handle that complexity but I shouldn’t have to. My hot take is that I don’t mind eating the (generally minimal) performance hit because the safety of an abstraction is more important than its performance. ↩︎
-
If we have to handle a deletion event for our local node, I’d be super confused. However, knowing K8s, I would not be shocked if this is technically possible. ↩︎
-
AMD 7402P at 2.80GHz processor, 128 GB ECC memory, and a Mellanox ConnectX-5 Ex 100 GB NIC. We assume that the authors used a single switch connected to each node along a 100 Gbps link. This is the only possible configuration on Cloudlab as far as we know. We used the same setup, as well as the same version of Ubuntu (20.04.6 LTS), Linux kernel (5.14.21), Antrea (v1.9.0), and Cilium (v1.12.4). However, we decided to use a newer version of Kubernetes (v1.32) – we tested multiple versions and checked the change logs and determined that it was unlikely that the K8s version would significantly impact networking performance. ↩︎
-
For iperf3, we use v3.7-3 on bare metal (Ubuntu 20.04 LTS) and v3.12-1 (Debian bookworm) in the container (using image networkstatic/iperf3); we found no performance differences between the two versions in testing. ↩︎
-
After deploying all of the containers for the benchmark, we wait for all containers to stabilize as reported by Kubernetes before running any workloads. We do not use a delay between any tests or a warm-up period as there is no indication that the original paper does so. ↩︎
-
Our best explanation for this is that the original authors ran this benchmark after setting up the Kubernetes cluster while ours were done on fresh hosts. ↩︎